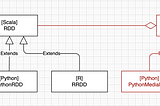
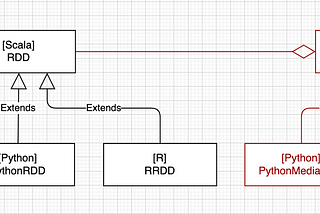
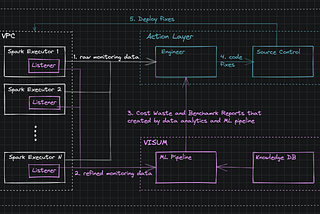
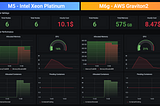
Dima StatzinITNEXTUnveiling Deep Signal: Part 1 — Defining the ProblemAbstract4 min read·Mar 22, 2024----
Dima StatzA Bottom-Up Approach for Choosing the Right Database for your workloadBackground5 min read·May 23, 2023----
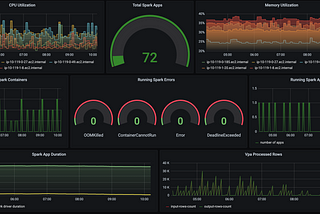
Dima StatzinITNEXTMonitoring Spark Streaming on K8s with Prometheus and GrafanaIntroduction5 min read·May 10, 2021--1--1
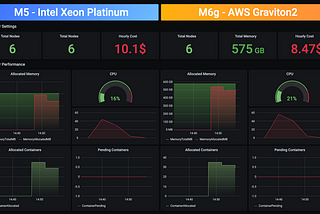
Dima StatzinITNEXTBenchmarking Graviton2 processors with Apache Spark workloadsIntroduction7 min read·Dec 28, 2020----
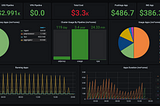
Dima StatzinITNEXTProcessing costs measurement on multi-tenant EMR clustersIntroduction6 min read·Nov 14, 2020----
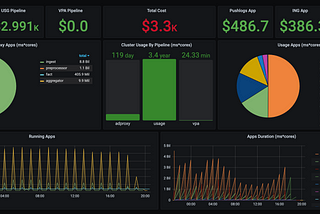
Dima StatzinITNEXTMigrating Apache Spark workloads from AWS EMR to KubernetesIntroduction10 min read·Sep 30, 2020--1--1
Dima StatzinITNEXTMonitoring the performance of software teams using Github, Jira, and GrafanaIntroduction8 min read·Jul 9, 2020----
Dima StatzinITNEXTMonitoring Distributed Jetty Servers in K8s using Prometheus and GrafanaIntroduction6 min read·May 28, 2020--1--1